
存储架构|聊聊 LSM Tree 强悍的设计
乐果 发表于 2023 年 10 月 09 日 标签:db
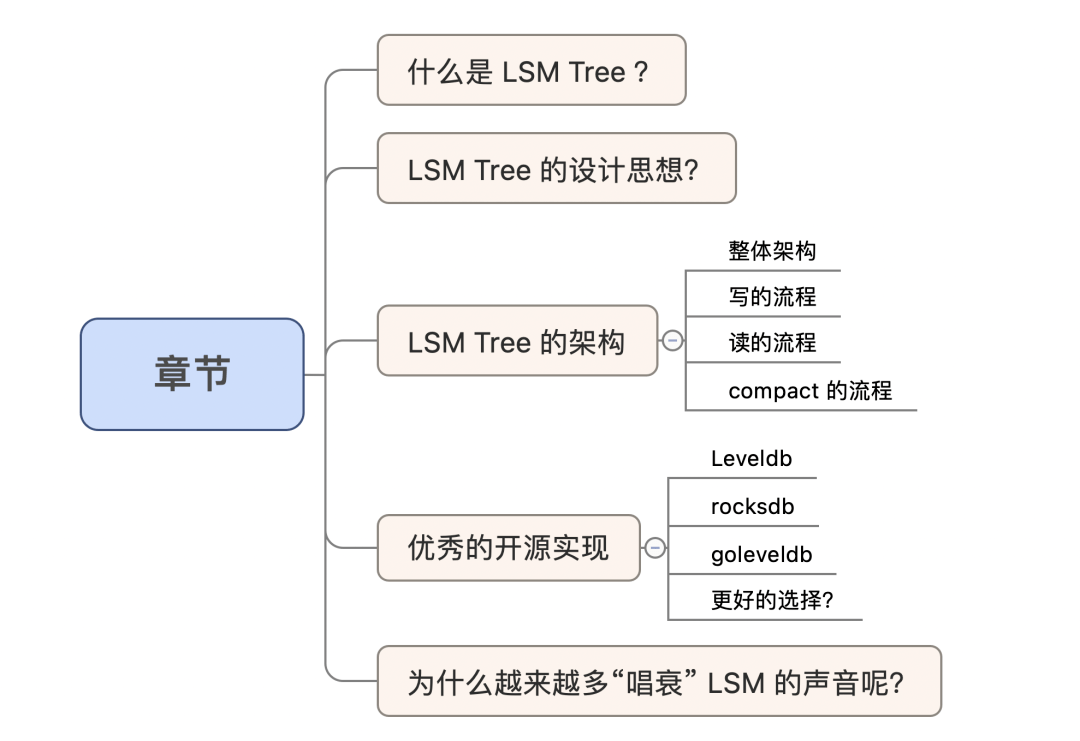
什么是 LSM Tree ?
LSM Tree 全名:Log Structured Merge Tree ,是一种在机械盘时代大放异彩的存储架构设计。LSM Tree 是一个把顺序写发挥到极致的设计架构。它的核心之一就是 log 文件。
笔者以几个问答来看下它的设计思想:
问题一:LSM Tree 存储引擎到底是什么?
不就是一个 key/value 存储引擎嘛。
问题二:用户写是怎么一个流程?
用户递交数据流程分为两步:写 log 文件,修改内存。所以会看到, 写的流程是非常简单的,用户的时延正常情况下就只包含这两步。
问题三:用户的删是怎么一个流程?
LSM Tree 为了极致的写性能把所有的更新操作都化作顺序写。也就是说, 删除也是写入。往存储里面写一条带删除标记的记录,而不是直接更新原来的数据。
问题四:这是一个持久化的存储吗?能保证掉电不丢数据吗?
是持久化的,因为 log 持久化了嘛。掉电不会丢数据,因为可以从 log 文件中恢复出来。恢复很简单,其实就是遍历 log 文件,然后解析出来就好。
那既然说到解析 log 文件,那么问题又来了,log 文件越大解析时间会越长,无限制增长这个是无法忍受的。
问题五:log 文件本身是不具备查找功能的,那怎么办?
log 文件其实是一种有时间顺序的文件,新数据不断的往后 append 写入,这种结构利于实现顺序写。但是 从用户 key/value 来讲是 log 的结构是一种无序的结构,它的查找效率非常低。
所以,自然而然,LSM 的架构里就需要引入一种新型的有序的数据结构,这个就是 sst 文件( 全名:sorted string table )。
所以,看到了,持久化的 log 数据向有序的 sst 文件转变是 LSM 的一个核心的流程。
划重点:sst 为有序的结构。
问题六:为什么 sst 文件经常很多个?
log 文件转变到 sst 文件是持续不断发生的。所以,很自然的,所以,系统中不会只有一个不断变大 sst 文件。因为一个庞大的空间这种查找效率会很低,并且每次重建一个有序的 sst 文件的开销会很大。
所以,在 LSM 的实践中,是划分了很多个有序的空间(sst 文件),每个文件内部又按照 block 划分,block 内部又按照 restart point 划分。
问题七:冗余或被删除的空间怎么释放?
把有效的数据从 sst 文件中读出来(删除或者被覆盖的旧数据丢弃)写到新的文件,然后修改指向关系,然后把旧的文件删掉。这个过程叫做 compact ,compact 是 LSM 设计中另一个核心流程。
LSM Tree 的设计思想?
存储的核心是读写,针对读写有不同的优化手段,比如预读,缓存,批量,并发,聚合等等。但是优化读和优化写能采用的手段其实不同,在机械盘时代,机械盘一定是瓶颈,它的随机性能极差,顺序的性能还能将就。
如果要优化 IO 读,有非常多的优化策略,比如使用多层缓存,CPU Cache,内存,SSD 等等,也可以采用丰富多彩的查询组织结构,比如各种平衡树型结构,提高读的效率。
但是,对于写,它一定是受限于磁盘的瓶颈。因为写的流程,数据落盘才算完。所以,对于写的优化手段非常有限,无论用什么手段,一定绕不过一点: 保持顺序,因为只有这样才能压榨出机械盘的性能。在写保持顺序的基础上,才去考虑加上其他的优化手段,比如批量,聚合等操作。
这正是 LSM Tree 的设计思想,考虑 极致的提升写的性能,读的性能则靠其他的手段解决。
下面介绍一些具体的 LSM Tree 项目的优秀实现。
LSM Tree 的架构
先声明一下,下面的架构设计就假定按照 leveldb 的实现介绍,虽然 rocksdb 也是 LSM 的实现但是加了很多复杂特性,介绍起来还挺麻烦的。
整体架构
先看看 LSM 的架构里有哪些东西吧,我们一个个说说:
CURRENT 是个文本文件,里面存的是一个文件名,记录当前可用的 MANIFEST 文件; MANIFEST 是一个二进制文件,里面存储的是整个集群的元数据; log 文件则是 wal 文件,是承接用户写 IO 的文件,这个文件的写性能直接关联用户的写性能; Memtable 和 Immutable Memtable 是内存结构,一般实现为一个具备查询效率的数据结构,比如跳表结构; ssttable 文件是内部生成的文件,每个文件都是按照 key 排序的文件。sst 内容格式都是一样的,但是大小不一定; Memtable(还有 Immutable Memtable)和 sstable 都是需要承接用户读 IO ,所以这两个里面都有大量的提升查询效率的手段;

从数据的格式转变来讲:
log 的数据和 memtable 的数据是对应起来的(同一份数据),log 的数据结构本质是无序的,所以必须依赖于 memtable 的查询效率; log 和 memtable 的这份数据下一步的去路就是 sstable 文件喽,这些个 sstable 文件属于 Level 0 ; Level 0 的 sstable 文件的去路是更底层 Level 的 sstable 文件喽,小的合并成大的,不断的往下沉喽;
思考一个小问题:log 存储的数据和 memtable 存储的数据量一般是一样大的?为什么?
log 是时间上有序但是内容上无序的格式,它上面的数据就只能依赖于 memtable 来提高查询效率。换句话说,它两就是一份数据,自然一样大。
写的流程
看了整体架构之后,简单看一眼用户的数据怎么存到系统的。步骤只有两步:
数据先写 log 文件;
数据再插入 memtable 结构中;
就这样,用户的写流程就算完了。由于 log 是持久化的,所以能确保数据不丢。这是对写流程的极致优化,只有一个写 log 的 io 消耗,并且是永远的 append 写入,简直是最理想的写流程。
读的流程
数据读的流程就略显复杂了,因为数据的范围太大了,那么多 sst 文件,那么多 key 的范围,可得好好查一查。
当然了,先从 memtable 开始,查不到就一步步往底层查,也就是到 Level 0,再到 Level 1,Level 2 等等。这里耗费的 IO 次数就不好说了,读的性能远比写要差多了。
既然聊到这里,大家都知道 sst 的读性能很差,那咋办?
加“索引”喽。和数据库的索引效果类似,都是为了提高读和查询效率的方法。所以,你仔细看会发现,在 leveldb,rocksdb 的实现离,有大量的索引结构。比如:
leveldb 把整个 sst 文件划分成一个个 block 小段,然后在 sst 尾端都有一个 index block,用来索引数据块。这样就能快速定位到 key 在哪一个 block 里; sst 文件中还有个 bloom filter 的小块,布隆过滤器喽,又给读提升了一点性能; 每个 block 里面呢,还有个 restart point 的数组,也能提高读性能;
比如,sst 的图示如下:

整体设计就是把 sst 切成一个个有序的小块,极大的提高查询的效率。每一个 block 里面又有按照 restart point 数组划分:

其实,还有很多讲究哦,这就不提了,太多了,很多都是为了 查询效率。
compact 的流程
leveldb 的 compact 分为两种:
minor compact :这个是 memtable 到 Level 0 的转变; major compact :这个是 Level 0 到底层或者底下的 Level 的 sstable 的相互转变;
这里值得提一点的是,sstable 每个都是有序的。但是呢,Level 0 的文件之间可能是有范围交叉的,但是 Level 0 之下的 sstable 文件则绝对没有交叉。正因如此,Level 0 的文件个数就不能太多,不然会影响查询效率(因为相互覆盖嘛,所以每一个都要查的)。
为什么会这样呢?
因为 Level 0 的文件是直接来源于 memtable,而没有去做合并。
优秀的开源实现
Leveldb
leveldb 是谷歌开源的一个 key/value 存储引擎,github 地址:https://github.com/google/leveldb 。由大佬 Sanjay Ghemawat 和 Jeff Dean 开发并开源。整个项目 c++ 实现,代码精致优雅,值得学习。
rocksdb
rocksdb 是 facebook 开源的一个 key/value 存储引擎,github 地址:https://github.com/facebook/rocksdb 。是基于 leveldb 项目的优化实现,适配 facebook 数据库团队的实际场景,特性要比 leveldb 多。整个项目 c++ 实现,代码实现也非常优秀,值得学习。
goleveldb
考虑到我们的读者很多都是 gopher ,那自然要推荐一个 golang 的版本,就是 goleveldb ,github 地址:https://github.com/syndtr/goleveldb ,这个项目实现的更小巧,值得学习推荐。
如果说,你是个 gopher,并且对 LSM Tree 感兴趣,那么完全可以去撸一撸 goleveldb 的源码。只要撸懂一个,那以后再深入就得心应手了。
更好的学习选择?用 Python 解析 LSM ?
其实,还有一个好选择,我们 fork 了 goleveldb ,会不定期更新一些代码注释,感兴趣的也可以看下,Github 地址:https://github.com/liqingqiya/readcode-goleveldb-master。
笔者在理解了 LSM 的结构之后,用 Python 脚本解析了一把 manifest 和 sst 文件,获益匪浅。贴上几个 python 解析 leveldb 的实例:

当你从不同的角度去看到存储,可以获得更深入的理解。比如,从 python、golang 两个角度来看数据。
比如,在 go 里面写入一个 uint64 的整型到文件,如下:
binary.BigEndian.PutUint64(buf, 0x123456789)
这个编码出来就是:[ 0x00, 0x00, 0x00, 0x01, 0x23, 0x45, 0x67, 0x89 ] 这 8 个字节,然后把这个 []byte 数组写到文件即可。文件里是这样的:
0x00, 0x00, 0x00, 0x01, 0x23, 0x45, 0x67, 0x89
那怎么用 python 读出来呢?
读出来也是一个字节数组,怎么转化成 uint64 的类型呢?是这样的:
struct.unpack( “>Q”, buf)
划重点:只要是涉及到数据传输的场景,字节数组的形式才是通用的形式。比如内存到磁盘,内存到网络等等,都是转成字节数组的形式,然后在别的地方按照特定规则构建出来就是无损的。
这里举这个例子,也只是想说明一点,LSM Tree 是一种有存储思想的架构设计,而不是跟具体的语言绑定的,一通百通。
为什么越来越多“唱衰” LSM 的声音呢?
归根结底还是硬件发展起来了。在原先的机械盘( HDD )时代,leveldb/rocksdb 的最佳实践就是一个磁盘只有一个写入源( wal ),所有的写请求都由这一个线程递交。这个是合理的,因为 HDD 最好的优化就是顺序化,并且一个线程串行递交请求也足以把 HDD 跑满。
但是自从 SSD 这种介质普及之后,一切都变了,单线程串行递交请求已经跑不满硬件了,比如 pcie 盘的通道就非常多,要并发全力压才能压的满。
还有就是 SSD 盘随机性能太好了,单就性能数据来讲和顺序的差不多。那这个时候 LSM Tree 为了顺序化而做的复杂的东西可能就显得优先多余了,反倒让系统变得复杂。
划重点:SSD 多通道并发、超高的随机性能是变革的核心因素。
那存储引擎的架构会怎么演进呢?
演进方向笔者也不确定。不过有一篇很出名的 FAST 上的论文 :《WiscKey: Separating Keys from Values in SSD-Conscious Storage》就讨论了在 SSD 时代,LSM 架构的优化思路。
并且立马就有开源的实现跟进了这个思路,比如 go 的 badger ,rocksdb 本身也有个集成了 BlobDB 的实验版本。
但实话说,LSM Tree 的架构会持续的优化,但会长时间持续存在,因为并不是所有场景都要用 SSD ,并且它不便宜。
总结
LSM Tree 是把写性能优化到极致的结构,当然了,这个极致的考虑就在于: 顺序 IO、批量操作 ; 当顺序并不是性能的关键因素的时候,LSM Tree 的架构就有点冗余。这个想想最近不断出现的针对 SSD 盘的优化思路就知道了; LSM Tree 的架构中没有覆盖写 ,log 永远 append,sst 也是读旧的写新的。CURRENT,MANIFEST 也是先写临时文件,最后 rename 一下。所以 LSM Tree 的安全、一致性就得到了保证; LSM 牺牲了的读性能就靠 各种“索引”结构 、各种 cache 来解决; compact 有两种:minor,major compact 。minor compact 是有序的 mem 数据(对应无序的 log 文件)到 sst 的转变。major compact 是 sst 内部之间的转变; 在 SSD 没出来之前, 写的有效优化手段只有顺序+批量,读的优化手段千奇百怪,从 LSM 的实现就可以窥见一二;
后记
今天聊聊 LSM Tree 的架构,分享一些设计思考,希望能帮到大家。点赞、在看是对我们最大的支持。
乐果 发表于 2023 年 10 月 09 日 标签:db